Reinhard Hanuschik, UVES QC Scientist
Version 1.0 (2001-03-09)
These parameters are defined by the QC scientist. They are measured by procedures which are, or will become soon, part of pipeline recipes.
Examples are:
QC1 parameters may be related to properties of a single frame (although for its measurement a number of input frames may be used), or to properties of a set of frames typically taken as representative for a whole night or even a longer period. An example of the latter case are the photometric zeropoints for a given night. Another example are colour coefficients which may be evaluated from a set of input data covering a period of weeks or months.
QC1 parameters are routinely used
Creating and assessing QC1 parameters is a core function of QC Garching. Despite their importance, neither the creation of QC1 parameters, nor their central storage or their evaluation is presently supported by DFS software. The purpose of this document is to propose a central database for storing QC1 values, and the interfaces needed for interaction with the database by a defined set of users.
The presently existing DFS components for processed VLT data are:
The calibration archive contains
The calibration archive is used to
The QC1 keywords are partly defined and filled into the FITS header by the instrument pipelines, or will be defined and filled within short. Throughout this document, we will assume the keywords exist and are properly filled.
Furthermore, there are ASCII tables specific for each instrument and data product which contain QC1 information for all data products which have hitherto been processed. This information is, due to the only recently realized implementation of the FITS QC keywords, not available in FITS headers, but only as flat ASCII files stored locally on the operational workstations. They are maintained by the responsible QC scientist.
The next natural extension step of the calibration archive is to store QC1 parameters in, and retrieve them from, a central repository. This is proposed here.
The effect of this step is
This aspect will become especially important in the future when the number of entries continuously increase and become eventually too large to be handled by simple UNIX tools. Last but not least, right now the handling of QC1 parameters is completely personalized, which will become a major problem at some time in the future since expertise about the tables is not distributed.
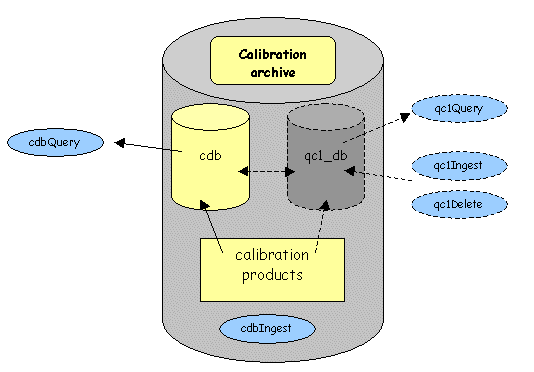
Figure 1: Proposed addition of the QC1 database qc1_db to the calibration archive
3.1 General requirements
The existing calibration archive consists of the calibration database (cdb) and a repository for the calibration products. The calibration database is filled, at the moment of ingestion using cdbIngest, from the FITS header of the file ingested.
For the purpose of storing the QC1 parameters, the calibration archive needs to be supplemented by the QC1 database (qc1_db). This is a relational database which forms an integral part of the calibration archive. qc1_db is fed from the FITS header of the file ingested, in the same way as cdb is fed. We will need an additional mechanism to feed qc1_db with historic QC1 data from local ASCII files (through qc1Ingest). We will also need a mechanism to delete entries (qc1Delete). Finally we need a tool to query qc1_db (qc1Query).
The ingestion process should be controlled by the QC scientist only (write access). The QC1 database should be queryable by the QC scientist and all other authorized people (read access). There should be a link between both databases to support e.g. joins.
Logically a distinction between cdb (containing the information about the hosted files in general) and qc1_db (containing QC1 information about the data in the files) is useful. This concept, however, needs not to be strictly translated technically. I.e., the qc1 database and the cdb database could be similarly structured parts of the same relational database.
3.2 Proposed structure
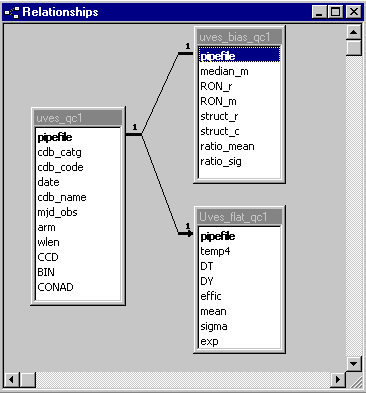
Figure 2: Structure of qc1. Example here: the UVES general QC1 table (uves_qc1) and two linked tables, uves_wave_qc1 and uves_bias_qc1. Boldface marks the primary key.
The qc1 database will contain, for each instrument supported, a table <instrument>_qc1. For example, the UVES qc1 table would be uves_qc1. This table will host general information about the calibration products, such as their identifier, their MJD_OBS, category, relevant instrumental parameters and names in different naming schemes. Part of this information is already available in the corresponding cdb tables.
Linked to <instrument>_qc1 are tables which contain the QC1 information, i.e. <instrument>_<type>_qc1. E.g., the UVES master biases have entries in uves_bias_qc1. There is one such table for any calibration product which has entries in the cdb database.
Figure 2 shows an example for UVES, with the table uves_qc1 and two tables uves_bias_qc1 and uves_wave_qc1 which are linked to uves_qc1, through their primary key Pipefile. While uves_qc1 contains the general information about the calibration products, the linked tables contain, line by line, for each product category (here: master bias and master flats), the detailed QC1 information. The complete structure of these example tables can be found in the Appendix.
There will be n tables <instrument>_qc1 where n counts the number of instruments (or instrument modes). There will be m tables <instrument>_<type>_qc1 where m counts the number of archived categories (e.g. master bias, master flat, line table etc.).
The QC1 database is normally filled at the moment when a calibration product is ingested into the archive. All relevant information is then read automatically from the QC keywords in the FITS header.
Multiple ingestion of files should be supported. It can happen any time that a new version of a calibration product is ingested (since e.g. the old one has been improved). Even ingestion of an identical version should not lead to an error condition, since typically frames are ingested in bulk mode. The corresponding entries in the tables are then simply updated.
There may be certain types of calibration products without QC1 information. These should be recognized on the basis of their cdb_catg keyword.
There should be an additional mode of ingesting entries into qc1_db, namely a command line mode (proposed name: qc1Ingest) which allows direct insert (or update) of values into the tables. qc1Ingest is needed for the following cases:
In order to keep the syntax simple, qc1Ingest should use the format mechanism available e.g. in cdbIngest. This means the sequence and designation of all entries are defined through the format key, and all entry values are then given field by field.
Example:
There are many entries in an ASCII table bias.dat which is structured likeYou want to ingest them line by line using qc1Ingest into the proper qc1 table. You would use qc1Ingest in the following way:
qc1Ingest -instrume uves -cdb_code MBIA -format "cdb_name& &date& &mjd& &median_m& &RON_r& &RON_m& &struct_r& &struct_c& &ratio_mean& &ratio_sig& &CONAD& &bin& &CCD"
This will tell qc1Ingest to select the uves_qc1 table (from -instrume) and the uves_bias_qc1 table (from -cdb_code) for all following qc1Ingest commands (until a new format definition is done). The format key is evaluated to associate the key names and values. The tool then automatically finds from the definition of the tables that values for keys cdb_name, date, mjd go into uves_qc1 (plus enter 'master_bias' into key pro_catg and read key pipefile from the FITS header), and all other entries go into uves_bias_qc1 (plus filename). Further calls will look like
qc1Ingest -values "r.UVES.2000-02-10T12:33:41.470_0000.fits 20000210 584.801 145.994 3.691 2.495 -999 -999 -999 -999 0.600 2x2 B"
qc1Ingest <next line> etc.
There might also be the necessity to delete entries without overwriting them. A command line tool (qc1Delete) should cover this option. The motivation for this is that, as experience has shown, the definition and harvesting of QC information needs some initial probation period, typically one or two semesters. Only after that time the QC mechanism for a new instrument mode is stable. Therefore there will generally be an initial trial period with the need to delete entries or even keys.
Example:
You wish to delete the entry for r.UVES.2000-02-10T12:33:41.470_0000.fits. You would enter:
qc1Delete -instrume uves -pipefile r.UVES.2000-02-10T12:33:41.470_0000.fits
or
qc1Delete -instrume uves -cdb_name MBIA_000323A_REDL_1x1.fits
(both options should be possible).
If you would like to delete a certain key only, you would use qc1Ingest instead.
Read access to qc1_db is generally based on sql queries. In principle such queries could be generated by the QC scientists to whatever their needs are. However, since there may other customers, it seems useful to have at least a UNIX command line tool covering some typical use cases. At some later point in time, when such typical use cases have emerged, a graphical user interface may be created which may include graphical presentation of data for trending and enable web access.
A typical application for a command line tool will be:
give me all/selected QC1 values about UVES master_biases (mode-specific or general) between date1 and date2.
The tool for read access (qc1Query) should therefore be designed
From the present point of view, qc1Query should have the following options:
-instrume <e.g. UVES>
-cdb_code <e.g. MBIA>
-cdb_catg <either a specific one like MBIA_REDL_1x1.fits or ALL as default value>
-format <either a key list as in the example for qc1Ingest, or ALL as default value>
-time_from, -time_to <permitted values are date strings like 2001-01-20, or INF for plus/minus infinity; default values are INF>
The QC scientist being responsible for a specific instrument will define the corresponding parts of qc1_db. He/she will use the following tools routinely:
The Qc scientist will need restricted write access (where the restriction means: no write permission for changes of database structure; only insert/update/delete through qc1Ingest, cdbIngest and qc1Delete is allowed).
Any use by Paranal Science Operations will be restricted to full read access. Although a precise definition of what PSO may want to do is not yet possible, it is clear that there should be no other restriction. This means they are expected to use
Any use of qc1_db should follow the PSO use case, except for having the option to restrict read access. Queries by external users should be possible through a web interface only, with the options to restrict the read access to certain parts of it. The restrictions should be configurable.
It seems feasible to have a common web interface for QC1 queries, which has a part which is password protected (to fulfill the PSO use case).
|
type |
number of entries per year and CCD |
|
bias |
500 |
|
fmtchk |
1000 |
|
orderpos |
400 |
|
wave |
500 |
|
standard |
400 |
|
science |
1500 |
These numbers give a total of 4300*3 entries, or about 13.000, entries per year for UVES, where each entry (line) consists of typically 10-20 elements as defined in the Appendix.
A typical scenario for the design and filling of the instrument-specific part of qc1_db is the following:
Once step 3 is reached, the set of QC1 parameters for a new instrument (mode) is ripe for the implementation of the corresponding qc1_db branch. All surviving data accumulated in step 2 would then be ingested using qc1Ingest. All new data would be ingested "on the spot" using cdbIngest.
This approach will guarantee a maximum stability of the database structure
once it is coded, and minimize workload for modifications. Only minor modifications
of the tables would have to be expected (such as adding a new column to a table).
TBD:
Appendix: Complete sample set of UVES table definitions
NOTE: this list is not up-to-date. Check here for the most recent list.
A1. UVES tables
The following tables will be needed for the UVES part of qc1_db:
|
table |
description |
|
uves_qc1 |
general table for all uves qc1 information |
|
uves_bias_qc1 |
master bias QC1 |
|
uves_flat_qc1 |
master flat QC1 |
|
uves_fmt_qc1 |
format check QC1 |
|
uves_ord_qc1 |
order definition QC1 |
|
uves_science_qc1 |
science QC1 |
|
uves_std_qc1 |
standard star QC1 |
|
uves_wave_qc1 |
wavelength calibration QC1 |
A2. Products without QC1 information
The following UVES calibration products have (presently) no associated QC1 information (qc1Ingest should ignore them):
|
cdb_code |
|
PDRS |
|
PBKG |
|
PLI1 |
|
PLI3 |
|
PGUE |
A3 Structure of uves_qc1
|
key |
type |
default value |
NULL allowed? |
example |
how to access |
|
pipefile (primary) |
char |
none |
no (primary key) |
r.UVES.2001-02-10T12:33:41.470_0000.fits |
FITS keyword |
|
cdb_catg |
char |
none |
yes1 |
MBIA_REDL_1x1.fits |
derived from cdb_name |
|
cdb_code |
char |
none |
yes1 |
MBIA |
derived from cdb_name |
|
date |
char |
none |
no |
2001-02-10 (date of night) |
derived from cdb_name, or from PIPEFILE |
|
cdb_name |
char |
none |
no |
MBIA_000323A_REDL_1x1.fits (if CALIB) or r.UVES.2001-02-10T05:33:41.470_0000.fits (if SCIENCE) |
input parameter |
|
mjd_obs |
real |
none |
no |
51541. 322 |
FITS keyword |
|
arm |
char |
none |
yes |
RED |
derived from cdb_name, or FITS keyword |
|
wlen |
integer |
none |
yes |
5640 |
derived from cdb_name, or FITS keyword |
|
CCD |
char |
none |
no |
B = blue, L = red lower, U = red upper |
derived from cdb_name, or FITS keyword PRO CATG |
|
bin |
char |
none |
no |
1x1 |
derived from cdb_name, or FITS keyword |
|
CONAD |
real |
none |
yes |
0.6 |
FITS keyword |
1for QC1 values of SCIENCE frames
|
key |
type |
default value |
NULL allowed? |
example |
how to access |
|
pipefile |
char |
none |
no |
r.UVES.2001-02-10T12:33:41.470_0000.fits |
inherited from uves_qc1 |
|
median_m |
real |
-999 |
no |
196.029 |
QC FITS keyword |
|
RON_r |
real |
-999 |
no |
2.129 |
QC FITS keyword |
|
RON_m |
real |
-999 |
no |
1.763 |
QC FITS keyword |
|
struct_r |
real |
-999 |
no |
0.045 |
QC FITS keyword |
|
struct_c |
real |
-999 |
no |
0.138 |
QC FITS keyword |
|
ratio_mean |
real |
-999 |
no |
1.002 |
QC FITS keyword |
|
ratio_sig |
real |
-999 |
no |
0.001 |
QC FITS keyword |
ref_name? ref_date?
|
key |
type |
default value |
NULL allowed? |
example |
how to access |
|
pipefile |
char |
none |
no |
r.UVES.2001-03-10T12:38:41.403_0001.fits |
inherited from uves_qc1 |
|
temp4 |
real |
-999 |
no |
12.4 |
QC FITS keyword |
|
DT |
real |
-999 |
no |
0.1 |
QC FITS keyword |
|
DY |
real |
-999 |
no |
-1.8 |
QC FITS keyword |
|
effic |
real |
-999 |
no |
39.833 |
QC FITS keyword |
|
mean |
real |
-999 |
no |
398.3 |
QC FITS keyword |
|
sigma |
real |
-999 |
no |
47.34 |
QC FITS keyword |
|
EXP |
real |
-999 |
no |
10.0 |
QC FITS keyword |
|
key |
type |
default value |
NULL allowed? |
example |
how to access |
|
pipefile |
char |
none |
no |
r.UVES.2001-03-10T12:38:41.403_0001.fits |
inherited from uves_qc1 |
|
lambda_min |
real |
-999 |
no |
12.4 |
QC FITS keyword |
|
lambda_max |
real |
-999 |
no |
0.1 |
QC FITS keyword |
|
order_min |
int |
-999 |
no |
-1.8 |
QC FITS keyword |
|
order_max |
int |
-999 |
no |
39.833 |
QC FITS keyword |
|
DX_mean |
real |
-999 |
no |
398.3 |
QC FITS keyword |
|
DX_sig |
real |
-999 |
no |
47.34 |
QC FITS keyword |
|
DY_mean |
real |
-999 |
no |
10.0 |
QC FITS keyword |
|
DY_sig |
real |
||||
|
Xstb_med |
|||||
|
Ystb_med |
|||||
|
N_all |
|||||
|
N_sel |
|||||
|
TEMP4 |
|||||
|
PRESS |
A7. uves_ord_qc1
|
key |
type |
default value |
NULL allowed? |
example |
how to access |
|
pipefile |
char |
none |
no |
r.UVES.2001-03-10T12:38:41.403_0001.fits |
inherited from uves_qc1 |
|
order_min |
int |
-999 |
no |
-1.8 |
QC FITS keyword |
|
order_max |
int |
-999 |
no |
39.833 |
QC FITS keyword |
|
resid_min |
real |
-999 |
no |
398.3 |
QC FITS keyword |
|
resid_max |
|||||
|
resid_mean |
|||||
|
resid_sig |
|||||
|
N_all |
|||||
|
N_sel |
A8 uves_wave_qc1
|
key |
type |
default value |
NULL allowed? |
example |
how to access |
|
pipefile |
char |
none |
no |
r.UVES.2001-03-10T12:38:41.403_0001.fits |
inherited from uves_qc1 |
|
lambda_min |
real |
-999 |
no |
12.4 |
QC FITS keyword |
|
lambda_max |
real |
-999 |
no |
0.1 |
QC FITS keyword |
|
order_min |
int |
-999 |
no |
-1.8 |
QC FITS keyword |
|
order_max |
int |
-999 |
no |
39.833 |
QC FITS keyword |
|
resid_mean |
|||||
|
respow_mean |
|||||
|
respow_sig |
|||||
|
DX_mean |
|||||
|
DX_sig |
|||||
|
N_all |
|||||
|
N_res |
|||||
|
N_sel |
|||||
|
temp4 |
|||||
|
slitw |
A9 uves_std_qc1
|
key |
type |
default value |
NULL allowed? |
example |
how to access |
|
pipefile |
char |
none |
no |
r.UVES.2001-03-10T12:38:41.403_0001.fits |
inherited from uves_qc1 |
|
mean_raw |
real |
-999 |
no |
12.4 |
|
|
mean_resp |
real |
-999 |
no |
0.1 |
|
|
lambda_min |
|
|
|
|
|
|
lambda_max |
|
|
|
|
|
|
n_order |
|||||
|
max_eff |
|||||
|
lambda_eff |
|||||
|
temp4 |
|||||
|
slit_w |
|||||
|
slit_l |
|||||
|
airmass |
|||||
|
conad |
|||||
|
object |
A10 uves_science_qc1
|
key |
type |
default value |
NULL allowed? |
example |
how to access |
|
pipefile |
char |
none |
no |
r.UVES.2001-03-10T12:38:41.403_0001.fits |
inherited from uves_qc1 |
|
mean_raw |
real |
-999 |
no |
12.4 |
|
|
mean_red |
real |
-999 |
no |
0.1 |
|
|
mean_err |
|
|
|
|
|
|
lambda_min |
|
|
|
|
|
|
lambda_step |
|||||
|
temp4 |
|||||
|
slit_w |
|||||
|
slit_l |
|||||
|
s_n |
|||||
|
airmass |
|||||
|
obj |
|||||
|
seeing |
|||||
|
fwhm |
|||||
|
delta_temp4 |
A11 uves_sky_qc1
Note: this table is a dummy table which presently is not needed. It is introduced here to illustrate the typical use of a table with night-based rather than file-based information (such as photometric zeropoints for FORS1 or ISAAC).
|
key |
type |
default value |
NULL allowed? |
example |
how to access |
|
mjd_obs |
char |
none |
no |
|
tbd |
|
date |
date |
none |
no |
2001-02-13 |
|
|
<settings> |
real |
|
no |
0.1 |
|
|
sky_bright |
|
|
|
|
|
This proposal uses the pipefile name (primary FITS keyword) as primary key for the tables. The reason for this is that the qc1_db should not only be able to host QC1 data for calibration data (in which case cdb_name would be a better choice since this is used by the cdb database already), but also QC1 information about reduced science data. There, only pipefile is available. Since a translation from cdb_name to pipefile is easy (simply evaluate the PIPEFILE keyword of the calibration file), the use of pipefile as primary key is more versatile.