
Their nodes participate in a binary relationship type (arcs), forming a tree graph. Each node has a maximum of one parent but potentially has many children. Different branches of the tree may have different depth. If your dimension has multiple roots, you can view those roots as a null parent's children, making a single tree with a null root.
The graph-defining binary relationship is a step relationship. Such a relationship is exemplified by "is parent of," "immediately reports to," or "is part of." Dimensions often have a classifying criterion (reporting, containment); however, you can use explicit hierarchies for arbitrary segmentation hierarchies, such as the ones classifying markets or customers. In such cases, classification rules vary from branch to branch and level to level.
"Transitive closure" refers to the set of generated transitive relationships. For example, you can define ancestor as either a parent or a parent's ancestor-- the same as defining ancestors as parents, parents of parents, parents of parents of parents, and so on. Similarly, you can define "reports to" as the relationship between any two organizations connected by a chain of "directly reports to" relationships. Finally, you can derive the "includes/is used in" relationship as a chain of "part of" relationships.
From now on, instead of abstract constructs, we'll adopt the organization
and the reporting relationship to illustrate the concepts presented. The
following relation identifies such an organizational entity:
org(TID, PID, NAME, other properties...)TID is the "token ID" serving as the organization dimension's surrogate name. The PID is the "Parent ID," denoting a reference to the parent organization. Because this is a hierarchical structure, only one parent per node is possible. The highest level organizations will have no parent; the PID is either NULL or the default value. For the purposes of our example, we will use numeric TIDs and PIDs and NULL in the top node PIDs to denote "no parent." In OLAP queries, you filter the dimension by selecting all organizations reporting to a given organization directly or indirectly. This filtering operation is particularly useful if you combine it with other dimension filters and join it to a fact in one SQL statement. Figure 1 shows the direct reporting relationships.
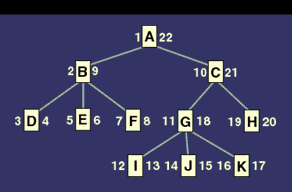
Let's say that you need to extract all unit expenses incurred under organization X. You'll either have to traverse the organizational structure for every such query, or prestore the table's transitive closure relationship. You can successfully traverse the structure using SQL extensions, such as the CONNECT BY clause in Oracle, or a recursive union of the DB2 family. You can also do this procedurally by reading X's successive layers of children, but you can't use such procedures as part of larger SQL queries.
The "prestored transitive closure" approach involves an intermediate table that contains X's descendents, and a join to the org table. The intermediate table is either temporary, generated every time you issue a query, or permanent, containing the transitive closure of the "reports to" relationship.
There are disadvantages to each of these solutions. The first
actually "walks the structure," requiring multiple requests that let you
extract children sets for each node you retrieve. The advantage of this
approach is that it doesn't introduce any update anomalies because you
don't maintain redundant data. The second solution uses set processing,
but it requires that you maintain a very large redundant table and deal
with the associated update anomalies. For example, a tree five layers deep
with a fan-out of 10 children per node has a total of 11,111 nodes and
11,110 parent-child relationships. But there are more than 11,000,000 ancestor-descendent
relationships in the transitive closure. A single maintenance operation
may affect more than one million of these ancestor-descendent relationships.
The cost of this approach grows geometrically as the fanout and depth grow.
This option is undesirable only because of maintenance complications and
the lack of scalability.
Let's call these two numbers L and R for the left and right one,
respectively. These attributes encode the organizational entity's complete
hierarchical ordering so you can use them in set queries. The following
rules govern their use:
(Li < Lj < Ri) <=> i ancestor of j
(Li < Rj < Ri) <=> i ancestor of j
You can view the L and R numbers as intervals. Each parent's interval covers the sum of its children's intervals, which define a topological ordering over the nodes. Numbering the nodes of a tree depth-first and traversing the nodes from left to right result in assigning L and R values. The enumeration process visits each node twice coming once from the top and a second and last time from below. The process keeps a running counter that dispenses sequential values, and assigns the L value at the first visit and the R value at the second visit. By following a depth-first left-to-right path, we insure that the process visits all the descendants of a node between its first and second visit. Figure 1 shows this numbering sequence.
Listing 1 shows two queries and a view. Case 1 returns the ancestors,
and Case 2 returns the node descendents named QNAME. The "from" clause
contains two references to the ORG table. "A" is the correlation name for
the "ancestor" role, and "D" for the "descendent" role. All queries use
the same predicate to restrict the descendent nodes' L values to fall in
the (A.L..A.R) range.
Case 1: Query of organization ancestors of QNAME (reporting chain up) select A.NAME, . . . from ORG A, ORG D where D.NAME = :QNAME and D.L between A.L and A.R Case2: Query returning set of all direct and indirect reports to node identified by :QNAME as of :QDATE: select D.NAME, . . . from ORG A, ORG D where A.NAME = :QNAME and D.L between A.L and A.R Case 3: View returning ANAMEs of ancestors of :descendents DNAME as of :QDATE; create view org_anc (DNAME, ANAME, . . .) as select D.NAME, A.NAME . . . from ORG A, ORG D where D.L between A.L and A.RListing 1. Tree Queries.
The view in Case 3 relates descendents and ancestors. You can use this view to find ancestors given a list of descendents, or to find descendents given a list of ancestors. If you display the contents of the view, you'll find the transitive closure table contents previously discussed. Instead of joining the transitive closure table, we'll use the "between" predicate captured in the view to do the filtering. Having faith in the optimizer, the DBMS will push selections through the view to develop a plan equivalent to Case 1 or 2.
You may ask: "Why don't we use a hierarchical keyword to achieve
the same result?" For example, an IP address-like scheme enumerates the
nodes of a tree as 1,1.1,1.2,1.3,1.1.1, and so on. The problem with this
scheme is that you have to start all qualifications from the top. Otherwise,
you'll have to scan the whole index or table. With the L and R enumeration
however, you can anchor your search at any level, relate any node to any
other one, and still employ matching index scans.
The L and R method has a level of magnitude performance advantage over any recursive SQL method, such as the SQL recursive union or Connect By clause. The node enumeration captures the nodes' topological ordering once, thus enabling transitive closure in one simple step, as opposed to multiple invocations. Detecting whether two nodes have an ancestor-descendent relationship normally requires the path traversal from one node to the other. Using the L and R numbers, however, you can test any two nodes using a simple between clause--without traversing the graph. Because the L and R method doesn't need to traverse the structure, more selective predicates may filter down the qualifying rows before applying the ancestor-descendent qualification. In recursive SQL, path traversal has to happen on unconstrained node sets, postponing highly filtering predicates until after the paths are traversed exhaustively.
L and R descendant selection subqueries scale well, even in MPP, share-nothing environments. The simple ancestor-descendent range test is partitionable and combined with other partitionable filtering predicates and achieves distributed dimension qualification. Recursive SQL requires multiple, directed invocations of the children-seeking query before applying other predicates. This approach pays for latency delay roughly proportional to the depth of the traversed tree.
Schema: org TID, PID, NAME, L, R, LEVEL... type TID, PID, NAME, L, R, CLASS, POSTING? period WK_END_DT, MONTH, YEAR cost ORG, TYPE, PERIOD, AMT Transitive Closure Views: create view org_tc (DTID,DNAME, ATID,ANAME, . . .) as select D.TID,D.NAME, A.TID, A.NAME . . . from ORG A, ORG D where D.L between A.L and A.R create view type_tc (DTID,DNAME, ATID,ANAME, ...) as select D.TID,D.NAME, A.TID, A.NAME . . . from TYPE A, TYPE D where D.L between A.L and A.R Query using Views: select O.ANAME, T.ANAME,P.MONTH,sum(AMT) from ORG_TC O, TYPE_TC T, PERIOD P, COST C where P.WK_END_DT between 1/1/1998 and 8/1/1998 and O.ALEVEL = 'DEPT' and T.DCLASS = 'LABOR' and T.ALEVEL = 'S' and P.WK_END_DT = C.PERIOD and T.TID = C.TYPE and O.TID = C.ORG group by O.ANAME, T.ANAME, P.MONTH order by 3,1,2 Query using nested SQL: With ORG_TC as (select distinct D.TID, A.NAME from ORG A, ORG D where D.L between A.L and A.R and A.LEVEL = 'DEPT' ), TYPE_TC as (select distinct D.TID,A.NAME from TYPE A, TYPE D where D.L between A.L and A.R and D.CLASS = 'LABOR' and A.LEVEL = 'S') select O.NAME, T.NAME,P.MONTH,sum(AMT) from ORG_TC O, TYPE_TC T, PERIOD P, COST C where P.WK_END_DT between 1/1/1998 and 8/1/1998 and P.WK_END_DT = C.PERIOD and T.TID = C.TYPE and O.TID = C.ORG group by O. NAME, T. NAME, P.MONTH order by 3,1,2Listing 2. Dimensions in Context
Let's assume that we're seeking all labor charges grouped by month, at the organization's summary cost type level (TYPE.LEVEL = 'S') and department level. Listing 2 shows two query forms. The first one uses the transitive closure views, while the second exploits nested SQL and the SQL3 WITH clause. The first implementation is appropriate for any DBMS with an optimizer avoiding unnecessary view materialization, such as Oracle. The DB2 family supports either form; with slight modification, we can use temporary intermediate tables to implement the second form in Sybase.
You may have to deal with one complication: Dimension selections
contain no duplicates during the join to the fact table. You can often
guarantee this from the selection criteria alone. However, in cases in
which you provide lists of ancestors with one being descendent of the other's,
you may end up selecting the same descendent multiple times. Listing 2's
nested SQL example uses the DISTINCT keyword in dimension subselects to
guarantee duplicate elimination.
accept constant SKIP;
let A: array of { TID: primary key of org,
L: integer = 0,
R: integer = 0}
indexed by i = 0;
initialize integer: Counter = 0 ;
load root nodes using
select TID, 0, 0
from ORG
where PID is NULL ;
load each into A after incrementing i by 1
i is left pointing to the last element loaded
while i > 0 do process last node of array until empty:
if A[i].L = 0
set A[i].L := ++ Counter
append children of A[i].TID to A using
select TID, 0. 0
from ORG
where PID = A[i].TID
load each into A after incrementing i by 1
i is left pointing to last element loaded
else
set A[i].R := Counter + SKIP
update ORG[TIDi] using
update ORG
set L = A[i].L
R = A[i].R
where TID = A[i].TID
decrement i by 1
endif
repeat;
Listing 3. L and R Generation Algorithm
The algorithm starts by reading all nodes that don't have a parent and stores them in an array. The while loop processes the last array element by assigning the next L value from an incremented counter, and then appends all its children to the array. The while loop iterates, similarly assigning L values and appending the children of the last element it finds on the array until the last element is a node with no children. The array now contains concatenated consecutive children sets along one path of nodes defined by the lexicographically highest keys of each level.
In its next iteration, the while loop, still pointing at the last element, will execute the "else" side of the "if" statement, because the L value will now be nonzero. This code block assigns the R number of the childless element after incrementing the counter by the constant SKIP value. The code block updates the database and continues processing with the next item on the left in the array being the last element. If the while loop finds an unassigned L value that's a member of the same child set and follows the "if" section of code, the loop assigns an L value, appends its children, and so on. If, on the other hand, an L value is already assigned, all of this node's children are processed and stored in prior iterations. The "else" section of the code assigns the R and writes the node to the database before proceeding with the next node on the left.
Every time you enter the while loop, the following assertions are always true:
The algorithm uses the array as a stack to process the tree in layers. It reads and updates each node once. Consequently, the algorithm's cost is of the order of the number of nodes in the tree.
You can improve the performance of this algorithm by avoiding the attempts to retrieve children from leaf nodes. You will have to mark all leaf nodes up front using a "Lowest Level" indicator. You can assign the appropriate value to the Lowest Level (LL) indicator as part of the initialization step of the algorithm, using two set update operations:
Update ORG set LL = Y;
Update ORG set LL = N where ORG.TID not used as a PID
The first update initializes all LL indicators, while the second marks all TIDs used as Parent IDs. By enhancing the while clause to use the LL value, you can avoid making unproductive attempts to extract children from nodes whose LL value is Y. The enhancement costs two table scans; you can justify this cost if the leaf node number is significantly larger than the nonleaf ones.
A word of caution: This algorithm assumes that the PID references
do not form cyclic paths. If inserting or updating the table and the PID
value guarantee the purity of the tree, the algorithm will be adequate.
Otherwise, you need to add an "occurs check" to ensure that every time
you read a new layer of children into the array A, none of these children
will appear in their respective ancestors' paths.
When should you prefer recursive hierarchies over fixed ones?
There are three motivations for leaving the security and simplicity of
fixed hierarchy designs to pursue recursive designs:
Recursive hierarchies are desirable because they're flexible and are less of a performance concern. But keep in mind that they introduce a degree of complexity. Make sure that your front-end tools generate the proper SQL and that you work out a way to maintain them. Validate performance expectations using realistic size dimension and fact tables with respect to your DBMS and optimizer.
Recursive hierarchies can also implement slowly changing recursive dimensions using versioning or Ralph Kimball's "Type 2" design. The result is a very powerful, general dimension archetype.
Michael Kamfonas is chief architect and director of data warehouse technology for Lockheed Martin's Integrated Business Solutions, based in Valley Forge, Pa. In the past 12 years he designed multimillion dollar solutions for Fortune 500 businesses and government in diverse technology environments. You can email Michael at michael.kamfonas@lmco.com.
search
- home - archives
- contacts - site
index
Copyright © 1998 Miller Freeman Inc. All Rights Reserved
Redistribution without permission is prohibited.
Questions? Comments?
We would love to hear from you!