Common DFOS tools:
|
| dfos = Data Flow Operations System, the common tool set for DFO |
| PHO ENIX |
IDP processing instances |
Find here an overview of the characteristics of the currently existing PHOENIX instances:
| UVES | XSHOOTER | GIRAFFE | GIRAFFE_STACK | HAWKI | KMOS | MUSE | MUSE_DEEP |
overview | schema for AB source |
Find all current release descriptions under http://www.eso.org/sci/observing/phase3/data_streams.html.
The UVES PHOENIX process was the first one to be implemented, producing UVES IDPs since 2013. It builds on the experience from the first reprocessing project (UVES data 2000-2007), not yet in the PHOENIX style. It supports the ECHELLE mode (with and without SLICERs), but not the extended mode and not the FLAMES/UVES (MOS) data.
In its current form, it is providing OB stacks if more than one input file per wavelength range exists, and single OB-based spectra if not. Ancillary files are added, like the single-exposure spectra for stacks, the 2D spectra, andQC reports.
Before 2015-07, the stream has been reprocessed with new master calibrations, in order to be as complete as possible for the early years of UVES. After that date, historical ABs and masters are used. The stream provides a flux calibration with master response curves that are versioned historically. This is available for certain standard setups but not for all. Hence all IDPs in these standard setups come flux-calibrated, while the IDPs for the unsupported setups come without flux calibration.
To observe:
History: http://qcweb/UVES_STACK/monitor/FINISHED/histoMonitor.html for the current stream; earlier streams: http://qcweb/UVESR_2/monitor/FINISHED/histoMonitor.html (post-2007) and UVESR_3 for period 2000-2007.
Monitoring of quality: automatic scoring system, with a dedicated qc1 database table. A QC monitoring process is available on the WISQ monitor.
Stream processing: in the standard monthly way; can also be done on a daily basis. Requires the master calibrations to be available, which is normally the case within a few days. Within the monthly loop, a given day is processed in the standard CONDOR way: ABs first, then QC reports.
The XSHOOTER PHOENIX process supports all three SLIT modes, but not IFU. The STARE stacks are not combined but processed individually (because it is impossible to read from the headers if stacking would be appropriate or not).
It uses the existing historical ABs (until 2020-12) and the existing historical master calibrations. Since 2020-12, ABs are created on the fly for the IDPs. The IDP process provides a flux calibration with master response curves that are versioned historically. This scheme was modified for the period since 2015-04 due to lamp efficiency curve changes. Flux calibration is available for all setups, hence all XSHOOTER IDPs come flux-calibrated. A telluric correction in the NIR arm is not provided. The telluric standard stars are also processed into IDPs.
To observe:
History: http://qcweb/XSHOOT_R/monitor/FINISHED/histoMonitor.html | http://qcweb.hq.eso.org/XSHOOT_R2/monitor/FINISHED/histoMonitor.html | http://qcweb.hq.eso.org/XSHOOT_TELL/monitor/FINISHED/histoMonitor.html
Monitoring of quality: automatic scoring system, with a dedicated qc1 database table.
Stream processing: in the standard monthly way, can also be done on a daily basis. Requires the master calibrations to be available, which is normally the case within a few days. Within the monthly loop, a given day is processed in the standard CONDOR way: ABs first, then QC reports.Since 2017-11, the science data and the telluric standard stars are processed together in one IDP batch.
The GIRAFFE PHOENIX process partly uses the existing historical ABs and the existing historical master calibrations. The early data (from 2003/2004) have seen the phoenix 2.0 project GIRAF_M which constructed new master calibrations (they were previously not existing). Based on them, the tool phoenixPrepare has been developed to use calSelector for the creation of the science ABs. These new ABs, together with the historical ABs for later periods, were then used to create the historical batch.
The PHOENIX process covers the Medusa1/2 modes (MOS), but not the IFU modes. GIRAFFE IDPs come per science fibre, which means anything between 1 and 120 (typical number: 80-100) spectra per raw file. SKY and SIMCAL fibres are not producing IDPs but are added as 2D ancillary files to each fibre-based IDP.
GIRAFFE IDPs are processed at the single-file level. OB stacks have been added later, see the GIRAFFE_STACK process below.
The process does not provide a flux calibration. Data come on a heliocentric wavelength scale.
The GIRAFFE PHOENIX processing stream has been terminated in 2018-02. It has been replaced by the GIRAFFE_STACK stream (see below) which includes both the single raw files and the OB stacks.
To observe:
History: http://qcweb/GIRAF_R/monitor/FINISHED/histoMonitor.html . There is also the monitor for the master calibration project, under http://qcweb.hq.eso.org/GIRAF_M/monitor/FINISHED/histoMonitor.html.
Monitoring of quality: automatic scoring system, with a dedicated qc1 database table. A WISQ monitoring process is done under http://www.eso.org/observing/dfo/quality/WISQ/HEALTH/trend_report_GIRAFFE_IDP_QC_HC.html.
Stream processing: not done anymore, it has been terminated in 2018-02 and continued as GIRAFFE_STACK stream, see below.
| before 2018-02 | GIRAFFE stream | GIRAFFE_STACK back-processing |
|
| 2018-02 and later | GIRAFFE_STACK stream |
The GIRAFFE_STACK stream is an extension of the GIRAFFE stream which was based on single raw files. It adds, as a second step, the processing of candidate IDPs from an OB into a stacked product. Input files and product file are fibre-based. For example, if an OB contains 4 exposures of similar exposure time and the same setup, with 80 science fibres each, then in the first step 4x80 single spectra are produced, and in the second step each of the 4 single products per fibre is stacked into the final stack product, with 80 stack IDPs in total. The individual single spectra are added as ancillary files, as are the SKY and SIMCAL fibre 2D products.
In case of single-exposure OBs, the GIRAFFE_STACK stream also includes the processing of single exposures into final IDPs, in the same way as described above for the "old" GIRAFFE stream.
All historical GIRAFFE data (from 2018-01 and before) which had multi-exposure OBs have been reprocessed in order to have a complete record of stacked products whenever possible. The single-exposure OBs were not reprocessed. Because of the different scenarios for the HISTORY back-procesing (only multi-exposure OBs) and the CURRENT stream-processing (all OBs), there is a configuration flag PROC_MODE in config.pgi_phoenix_GIRAFFE_AB set to either HISTORY or CURRENT. This flag controls the processing scheme. It is also read by the idpConvert_gi tool, that needs to know whether the existing single-exposure products are final IDPs (for single-exposure OBs), or intermediate products for the final stack IDPs (for multi-exposure OBs). In the latter case, they are ingested as ancillary files.
This flag was relevant for the back-processing of the stacks. Now, for the stream production, it is always set to CURRENT.
History: http://qcweb/GIRAF_STACK/monitor/FINISHED/histoMonitor.html
Monitoring of quality: automatic scoring system, with a dedicated qc1 database table.
Stream processing: in the standard monthly way. The daily call is also possible (but less efficient). The AB processing has two steps: one for the initial giraffe_science recipe (for all raw files), the second for the esotk_spectrum_combine recipe (only for the stack candidates). The first-step AB processing takes rather short (few seconds per raw file), the second-step a bit longer. The QC reports take long (up to one minute per fibre). The optimized processing scheme is therefore the QC job concentration: as many QC jobs run in parallel as possible. For simplicity, this is reached by collecting QC jobs (hence the name) rather than starting to split the QC jobs by fibre. Individual QC job are still executed sequentially. Therefore a daily processing may take almost as long as a monthly processing.
The monthly processing requires the master calibrations to be available, which is normally the case within a few days.
The HAWKI IDP stream has been set up as a standard phoenix process. ABs have been taken from the DFOS HAWKI source until 2020-12. Since then, they are created by phoenix.
History: http://qcweb/HAWKI/monitor/FINISHED/histoMonitor.html
Monitoring of quality: automatic scoring system, with a dedicated qc1 database table.
Stream processing: in the standard monthly way.
The HAWKI IDP stream has been set up as a standard phoenix process. ABs have been taken from the DFOS KMOS source until 2020-12. Since then, they are created by phoenix.
History: http://qcweb/KMOS/monitor/FINISHED/histoMonitor.html
Monitoring of quality: automatic scoring system, with a dedicated qc1 database table.
Stream processing: in the standard monthly way.
Find a detailed description of the MUSE PHOENIX process here. The related MUSE_DEEP process is described here.
Here is an overview of the technical aspects of the various phoenix processes and accounts.
| Instrument/ release |
hostname | N_cores | disk size/TB | disk space | pattern | schema for AB processing | QC reports | performance limited by | typical exectime | |
| AB | QC | |||||||||
| UVESR_2, UVES_R3, UVES_STACK | sciproc@muc08 | 32 | 7 | not an issue | monthly* | condor, daily | condor, daily | <1 min | 0.5 min | |
| XSHOOT_R, XSHOOT_R2, XSHOOT_TELL | xshooter_ph@muc08 | monthly* | condor, daily | condor, daily | 2-7 min | 0.5 min | ||||
| GIRAF_R | giraffe_ph@muc08 | monthly* | condor, daily | QCJOB_CONCENTRATION: monthly batch for efficiency | QC reports (because of 1 per fibre: ~100 per raw file) | 0.3 min | 30-40 min | |||
| GIRAFFE_STACK | giraffe_ph@muc08 | monthly* | condor, daily | QCJOB_CONCENTRATION: monthly batch for efficiency | QC reports (because of 1 per fibre: ~100 per raw file) | 0.3 min | 30-40 min | |||
| MUSE_R | Up to 4 instances: SLAVEs: muse_ph@muc09 (historical), muse_ph3@muc11 (exceptional), muse_ph4@muc12 (historical). MASTER: muse_ph2@muc10 |
32...56 | 3.5 ... 10 | to be monitored carefully (1 month of data about 3 TB if in 'reduced'; more if on $DFS_PRODUCT | daily | each account: 2-3 streams, INTernal** | serial | - AB processing in 2-3 streams - memory (0.5 TB each, sufficient for N=20 combination; 2 TB on muc11) |
5-30 min*** | 1 min |
| MUSE_DEEP | muse_ph3@muc11 | 56 | 10 | not an issue | by run_ID | 3 streams, INT | serial | - AB processing in 2-3 streams - memory (2 TB on muc11, ok for N=120) |
same | same |
| HAWKI_R | hawki_ph@muc08 | 32 | 7 | not an issue | monthly* | condor, daily | condor, daily | ... | ... | |
| KMOS_R | kmos_ph@muc08 | 32 | 7 | not an issue | ||||||
* can also be done daily, but then completeness needs to be carefully monitored
** most recipes run in 2-3 streams (using 24 cores each)
*** depending on AB type
| Instrument/ release |
active? | SCIENCE AB source | stacks or single raw files? | conversion from pipeline format to IDP required? | monthly batch: | ||||
| typical total number of files per month (ingested)**** | IDPs only | exec times per month [hrs] | size [GB] | ingestion time [hrs] | |||||
| UVESR_2 | qcweb: UVES | single | yes, conversion tool uves2p3 | 1,000***** | 1,000 | 1 | 1 | 0.5 | |
| UVES_R3 | qcweb: UVESR_2 | ||||||||
| UVES_STACK | yes | since 2015-07: qcweb, UVES_R3; before: phoenix, COMPLETE_MODE; plus AB_PGI for stack ABs; since 2020-12: ABs created by phoenix | single and stacks | yes, conversion tool uves2p3 | 3,000 | <1000 (stacks) | ... | ... | ... |
| XSHOOT_R, XSHOOT_TELL | no; TELL merged with XSHOOT_R2 | qcweb: XSHOOTER | single and stacks | no*** | 1,000 | 500 | 4 | 7 | 0.5 |
| XSHOOT_R2 | yes | qcweb: XSHOOT_R; since 2020-12: ABs created by phoenix | |||||||
| GIRAF_R | no | qcweb: GIRAFFE and qcweb: GIRAF_M* | single | no*** | 20,000 | 10,000 | 5 - 10 | 7 | 25 |
| GIRAF_COSMIC | no (merged with STACK) | qcweb: GIRAF_R | single | ||||||
| GIRAF_STACK | yes | qcweb: GIRAF_R and GIRAFFE; since 2020-12: ABs created by phoenix | single and stacks | no*** | same as GIRAF_R | ||||
| MUSE_R | yes | qcweb: MUSE_smart**; since 2020-12: ABs are created by phoenix and uploaded to MUSE_smart; then phoenix_prepare_MUSE creates the ABs for the higher processing steps | stacks | no*** | ... | ... | many ... | ...3000 | ... |
| MUSE_DEEP | yes | qcweb: MUSE_deep****** | deep stacks | no*** | n/a | n/a | n/a | ... | ... |
| HAWKI_R | yes | qcweb: HAWKI; since 2020-12: ABs created by phoenix | stacks | no*** | ... | ... | ... | ... | ... |
| KMOS_R | yes | qcweb: KMOS; since 2020-12: ABs created by phoenix | stacks | ||||||
* early epoch: mcalibs created with phoenix, ABs created with phoenixPrepare
** created
with phoenixPrepare_MUSE
*** pipeline format is IDP; tool needed for header manipulation
**** including ANC files
***** plus 1 png per IDP (not ingested)
****** created with phoenix_createDeep
 Data model: schema for AB source
Data model: schema for AB source
In the past (until 2020-12) the phoenix process took the DFOS SCIENCE ABs from qcweb. In 2020-12, this has been replaced by creating the ABs within phoenix.
No matter whether downloaded or created, phoenix then edits them with some PGI (in order to e.g. update pipeline parameters, unify static calibration schemes), and stores them after processing in a new repository. The idea is to have them there available in case of future further reprocessing projects. This might become an option (if e.g. a substantial algorithmic improvement would become available) or even a necessity (if e.g. a pipeline bug is discovered, resulting in an error with the already processed IDPs). Then, it is very advantageous to not start from the DFOS ABs again, apply all modifications to the ABs again, and then add the new improvements, but instead take the existing phoenix ABs and reprocess them directly.
This approach is generally called a data model: all information about the processing is stored for easy replay. In the phoenix case, one would start from the new AB source, turn off the old AB modification PGI, replace it, if needed, by a new one, and start the entire reprocessing with a new pipeline version, new parameters, new master calibrations etc.
The standard data model for IDP production is:
 |
Standard data model for PHOENIX: ABs are taken from the DFOS site, edited, processed, and stored under a new tree. |
For MUSE, there is the need to have an intermediate storage of ABs, and a final storage after editing and processing:
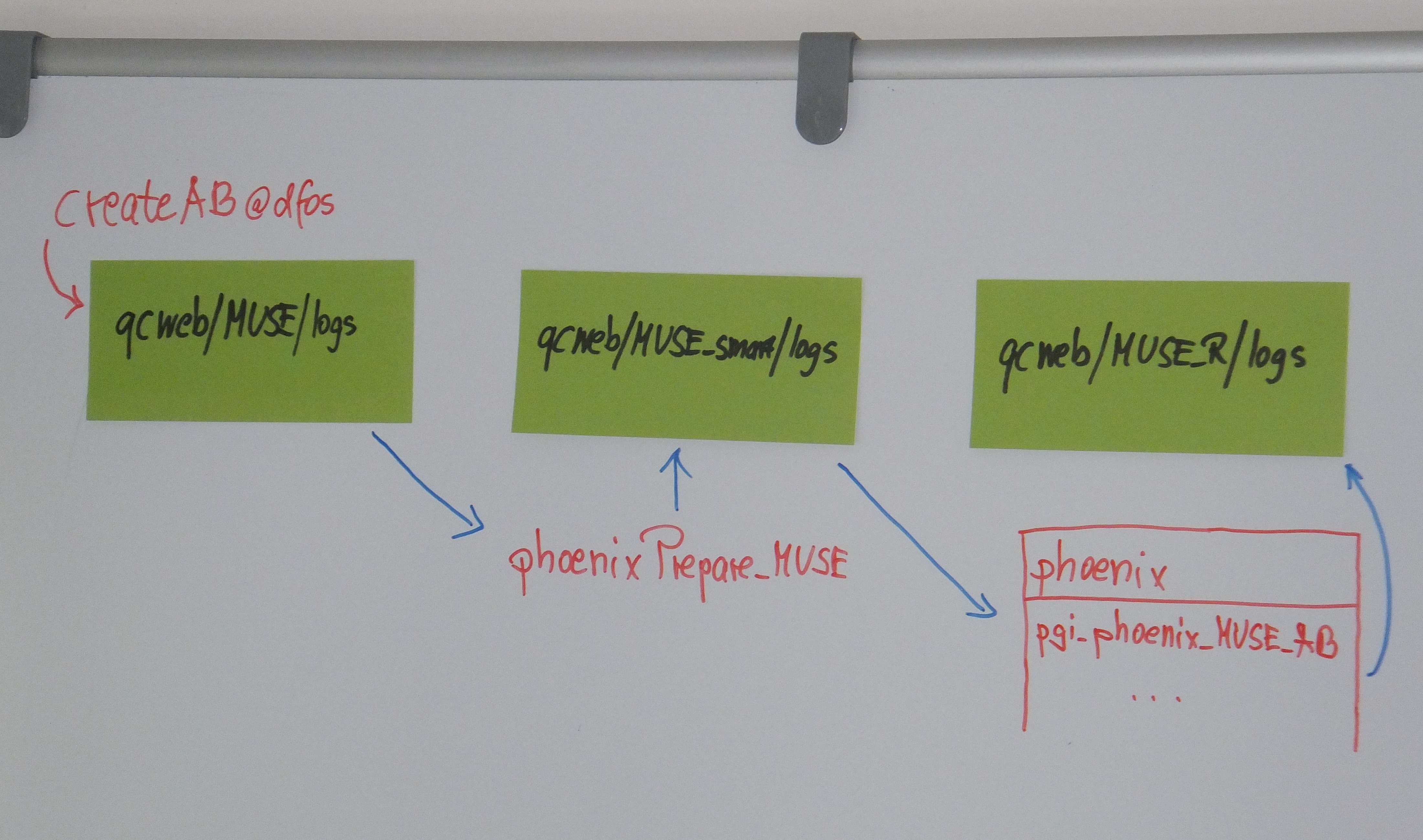 |
Data model for MUSE PHOENIX: ABs are taken from the DFOS site, get their input dataset modified, then are processed, and stored under a new tree. |
This chain is extended for MUSE_DEEP: the preparation tool (to create the DEEP ABs) takes the input ABs from MUSE_R and puts the output ABs into MUSE_deep, from where the phoenix process starts. The processed ABs then go to MUSE_DEEP.
If an existing IDP project would need to be reprocessed, it could take the phoenix storage and reprocess from there:
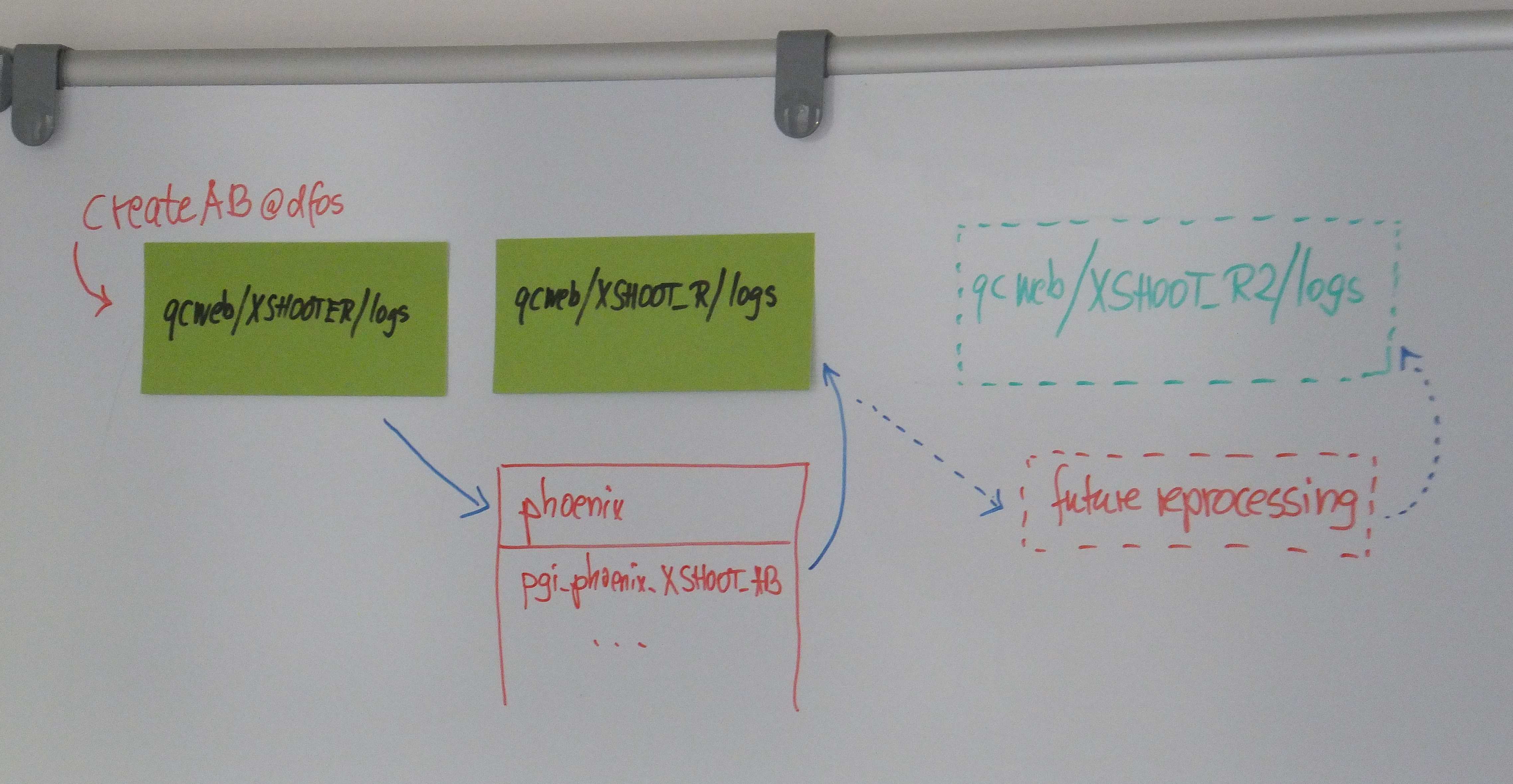 |
Data model for future reprocessing projects |
| Last update: April 26, 2021 by rhanusch |